
Pour analyser et comprendre automatiquement les demandes faites par les clients dans leurs e-mails, Julie se base sur l’intelligence artificielle (IA) et plus particulièrement sur le Traitement automatique du langage (Natural Language Processing (NLP) en anglais). Le NLP est un sous domaine de l’IA qui traite différents sujets, allant de la compréhension à la formulation de texte.
Les premières applications du NLP étaient axées sur la traduction automatique, comme en témoigne l’expérience de Georgetown-IBM (1954) qui visait à traduire automatiquement une soixantaine de phrases du russe vers l’anglais. Dans cette expérience, la traduction a été possible en utilisant 6 règles grammaticales et un ensemble de 250 éléments lexicaux.
 En 1964, un programme informatique nommé ELIZA a été développé. Le programme pouvait comprendre les réponses données par des utilisateurs pour différents scripts, afin de les traiter. Le plus célèbre de ces scripts fut DOCTEUR qui était la simulation d’une thérapie centrée sur le client (Rogerian Therapy). Pour simplifier, ELIZA réarrangeait les phrases et se basait sur quelques règles basiques de grammaire, afin de rendre le dialogue possible avec les utilisateurs. Le programme était si convaincant que certaines personnes croyaient parler à une personne réelle et n’avaient ainsi aucun mal à confier leurs secrets à ELIZA.
En 1964, un programme informatique nommé ELIZA a été développé. Le programme pouvait comprendre les réponses données par des utilisateurs pour différents scripts, afin de les traiter. Le plus célèbre de ces scripts fut DOCTEUR qui était la simulation d’une thérapie centrée sur le client (Rogerian Therapy). Pour simplifier, ELIZA réarrangeait les phrases et se basait sur quelques règles basiques de grammaire, afin de rendre le dialogue possible avec les utilisateurs. Le programme était si convaincant que certaines personnes croyaient parler à une personne réelle et n’avaient ainsi aucun mal à confier leurs secrets à ELIZA.
Jusqu’aux années 80, les tâches du NLP étaient principalement remplies grâce à des systèmes construits sur des ensembles complexes de règles écrites à la main, des systèmes dits experts (expert systems). Mais à la fin des années 80, avec la montée en puissance des capacités de traitement, les théories d’apprentissage automatique (à savoir le Machine Learning), ont été appliquées au NLP, rendant les systèmes experts obsolètes. Le Machine Learning vise à créer des modèles statistiques, capables de résoudre une tâche automatiquement, sans intervention humaine. Lorsqu’un algorithme d’apprentissage est suffisamment entrainé, le Machine Learning nous permet de construire des modèles robustes, non sensibles aux informations inconnues et/ou erronées, comme des mots mal orthographiés ou des mauvais tokens.
En tant que système contemporain, Julie repose sur le Machine Learning. L’un des problèmes que Julie résout en se basant sur cette approche est la classification de texte. La classification de texte correspond à l’action de catégoriser ( ou classifier) un texte donné en une seule, ou plusieurs, catégories prédéfinies (ou classes). En d’autres termes, en se basant sur des algorithmes de Machine Learning, Julie est en mesure de déterminer le type de rendez-vous en question (par exemple, « Réunion« , « Call » et « Déjeuner« ) en le classant dans l’un des types de RDV qu’elle a appris.
Pour définir le type de rendez-vous trouvé dans un email, Julie fait recours à un algorithme Support Vector Machine (SVM), formé sur un échantillon de rendez-vous, qui sont annotés manuellement en différentes catégories de rendez-vous. L’idée est d’associer les mots extraits de chaque demande aux catégories annotées correspondantes dans l’échantillon, et de généraliser sur l’ensemble des demandes reçues. Ainsi, le mot restaurant sera associé au type de rendez-vous « déjeuner » tandis que le mot skype-id sera associé à un « rdv téléphonique ». Pour représenter les requêtes d’une manière compréhensible pour l’algorithme, nous avons appliqué la méthode bag-of-words (BOW), qui traduit un texte écrit en langage naturel en une représentation vectorielle abstraite de mots, appelés des tokens ; chaque token correspondant à une dimension du vecteur. Dans une telle représentation, les tokens des mots fonctionnels (par exemple la, à, a) et des verbes modaux (par exemple est, ont) sont éliminés de sorte que seule le coeur de la demande est conservée.
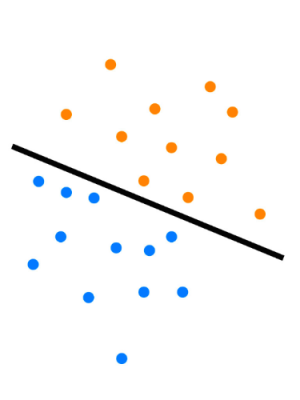 Le modèle SVM standard est conçu pour la classification binaire. L’objectif de la classification binaire est de trouver une limite de séparation qui divise toutes les données d’apprentissage extraites des échantillons, en deux classes (par exemple des points bleus contre les oranges, sur le schéma ci-contre). Dans un espace à 2 dimensions, le problème de classification consiste à trouver la ligne (marquée en gras sur le schéma) de telle sorte que la distance entre les deux points les plus proches se trouvant sur chaque côté de la ligne (appelée vecteurs de support) soit la plus éloignée possible. Cette séparation caractérise le modèle SVM. Ainsi, pour trouver la classification d’un nouveau jeu de données, il suffit de déterminer de quel côté de la ligne le point correspondant est situé.
Le modèle SVM standard est conçu pour la classification binaire. L’objectif de la classification binaire est de trouver une limite de séparation qui divise toutes les données d’apprentissage extraites des échantillons, en deux classes (par exemple des points bleus contre les oranges, sur le schéma ci-contre). Dans un espace à 2 dimensions, le problème de classification consiste à trouver la ligne (marquée en gras sur le schéma) de telle sorte que la distance entre les deux points les plus proches se trouvant sur chaque côté de la ligne (appelée vecteurs de support) soit la plus éloignée possible. Cette séparation caractérise le modèle SVM. Ainsi, pour trouver la classification d’un nouveau jeu de données, il suffit de déterminer de quel côté de la ligne le point correspondant est situé.
Julie peut résoudre tout problème de classification dans un espace à N-dimensions. En réalité, depuis que nous utilisons une méthode BOW pour traduire les demandes reçues en machines vecteurs, le nombre de dimensions auxquelles Julie doit faire face est beaucoup plus grand que 2 et correspond au nombre de tokens trouvés dans tout le vocabulaire extrait des exemples échantillonnés à la fin de l’étape d’apprentissage. Dans un espace à N dimensions, la séparation n’est plus une ligne à une dimension, mais un plan à N dimensions (à savoir un hyperplan).
En soi, le modèle SVM ne convient pas à la classification multi-classe (c’est-à-dire lorsque l’on veut classer les données fournies en plus de 2 catégories). Julie effectue ce type de classification pour classer les rendez-vous. Pour ce faire, nous appliquons un algorithme d’apprentissage automatique appelé classification One-vs-All. D’autres classificateurs d’apprentissage existent (par exemple One-vs-One), mais ils se sont avérés être beaucoup plus gourmands en termes de calcul et moins efficaces en classification de texte. En utilisant l’algorithme One-vs-All, nous avons formé 10 classificateurs SVM binaires séparés, chacun utilise le même échantillon de rendez-vous, qu’il sépare selon la taxonomie de rendez-vous définie chez Julie Desk ( « Réunion », « Appel », « Déjeuner » etc). Imaginons que le premier classificateur à former est appelé le classificateur « Lunch »; selon l’algorithme All-vs-One, les RDV exemples de l’échantillon d’apprentissage seront répartis de la manière suivante : d’un côté nous regroupons tous les exemples annotés avec l’étiquette « déjeuner » et de l’autre coté, nous regroupons tous les exemples restants comme étant des données identiques. Une fois l’apprentissage de chaque classificateur terminé, la classification d’un nouveau rendez-vous est un processus en deux volets : (i) classer le RDV par chaque SVM binaire formé séparément et (ii) déduire la classification finale en se basant sur le résultat renvoyé par chaque classificateur (par exemple, en utilisant une méthode de vote).
L’évolution du Machine Learning et du NLP ont conduit à l’émergence d’algorithmes «intelligents» et donné naissance à Julie. Grâce à ces avancées, Julie est capable de répondre à vos demandes et d’organiser vos rendez-vous. Mais ce n’est que le début ; l’apprentissage en profondeur est actuellement en train d’ébranler le domaine de l’IA, en fournissant d’excellents résultats à partir de méthodes basées sur les réseaux de neurones artificiels. Julie pourrait avoir encore plus de surprises pour vous …
Si vous avez des questions ou des remarques, n’hésitez pas à consulter notre page FAQ ou contacter notre équipe.