
To automatically understand client requests found in emails, Julie relies on Artificial Intelligence (AI) and, in particular, Natural Language Processing (NLP). NLP is a subfield of AI that deals with various problems ranging from text comprehension to text generation.
Early applications in NLP focused on machine translation, as evidenced by the Georgetown-IBM experiment (1954) which aimed to automatically convert about sixty sentences from Russian to English. In this experiment, the translation problem was solved using 6 grammatical rules and a set of 250 lexical items.
 In 1964 a computer program was developed, named ELIZA. It operated by processing users’ responses to scripts, the most famous of which was DOCTOR, a simulation of a Rogerian psychotherapist. Mostly, ELIZA was rearranging sentences and following some simple grammar rules, to make dialog possible with users. It was so convincing that some people believed they were talking to a person for real and told ELIZA secrets about their personal life.
In 1964 a computer program was developed, named ELIZA. It operated by processing users’ responses to scripts, the most famous of which was DOCTOR, a simulation of a Rogerian psychotherapist. Mostly, ELIZA was rearranging sentences and following some simple grammar rules, to make dialog possible with users. It was so convincing that some people believed they were talking to a person for real and told ELIZA secrets about their personal life.
From that time until the 80’s, NLP tasks were mainly solved using systems built on complex sets of hand-written rules, called expert systems. However, in the late 80’s, as a result of the increase of processing power, Computational Learning Theory (i.e. Machine Learning) derived from Computer Science, was introduced in NLP, making expert systems obsolete. Machine Learning aims to create statistical models, able to solve a task automatically, without any human intervention in the creation process. Providing that a learning algorithm contains enough training instances, Machine Learning is capable of building robust models, insensitive to unfamiliar and erroneous inputs, such as misspelling words and bad tokenization.
As a contemporary system, Julie relies on Machine Learning. One of the problems Julie is solving, based on this approach, is Text Classification. Text Classification is the task of categorizing (or classifying) a given text into one, or several, predefined categories (or classes). In other words, based on Machine Learning algorithms, Julie is able to determine which kind of appointment the request is talking about (e.g. “Meeting”, “Call” and “Lunch”), by classifying it into one of the types of appointments she has learned.
To predict the specific type of an appointment found in a request, Julie relies on a Support Vector Machine (SVM) algorithm, trained on a sample of appointments, annotated manually into appointment types. The idea is to combine all words extracted from each request to the related types annotated in the sample, and to generalize over all the training requests. Eventually, the word restaurant will be associated with the type of appointment “Lunch”, while the word skype-id will be associated with the “Call” one. To represent requests in a way the algorithm can understand them, we applied a traditional bag-of-words (BOW) method, which translates text written in natural language, in a vector of an abstract representation of words, called tokens; each token corresponding to one dimension of the vector. In such a representation, tokens coded for functional words (e.g. the, at, a) and modal verbs (e.g. is, have) are discarded such that only the substantial meaning of the request is preserved.
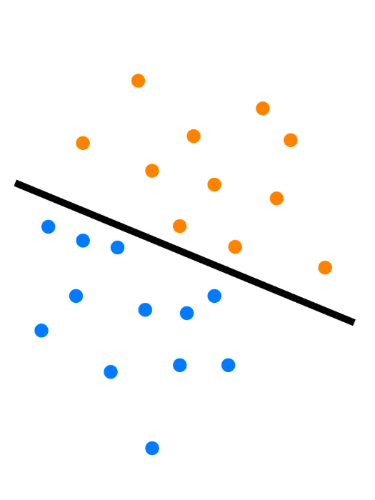 The standard SVM model is designed for binary classification. The goal of binary classification is to find a separation boundary that splits all training data taken from the sampled data, into two classes (e.g. blue points versus orange ones, on the diagram shown on the left-hand side here). In a 2-dimensional space, the classification problem consists in finding the line (marked in bold on the diagram) such that the distance between the two closest points found on each side of the line (called support vectors) is farthest away. This separation characterizes the SVM model. Thus, to find the classification of a new piece of data, one just needs to determine on which side of the line the corresponding point is located.
The standard SVM model is designed for binary classification. The goal of binary classification is to find a separation boundary that splits all training data taken from the sampled data, into two classes (e.g. blue points versus orange ones, on the diagram shown on the left-hand side here). In a 2-dimensional space, the classification problem consists in finding the line (marked in bold on the diagram) such that the distance between the two closest points found on each side of the line (called support vectors) is farthest away. This separation characterizes the SVM model. Thus, to find the classification of a new piece of data, one just needs to determine on which side of the line the corresponding point is located.
Julie can solve any classification problem in an N-dimensional space. In fact, since we used a BOW method to translate request messages in machine vectors, the number of dimensions Julie has to deal with is much greater than 2 and corresponds to the number of tokens found in the whole vocabulary extracted from the sampled examples at the end of the training step. In N-dimensional space, the separation boundary is no longer a 1-dimensional line but is an N-dimensional plane (i.e. a hyperplane).
Per se, the SVM model is not suited for multi-class classification (i.e. when one wants to classify given data into more than 2 classes). Julie performs such a classification, to classify appointments. To do this, we applied a Machine Learning algorithm called One-vs-All classification. Some other learning classifiers exist (e.g. One-vs-One) but they have been shown to be much more greedy in terms of computation and less efficient in solving Text Classification. Using the One-vs-All algorithm, we trained 10 binary SVM classifiers separately, each using the same sample of example appointments, split according to our taxonomy of appointments at Julie Desk (“Meeting”, “Call”, “Lunch”, and so on). If we say the first classifier to be trained is called the “Lunch” classifier, then, according to the One-vs-All algorithm, examples of the training sample will be split as follows: on the one hand we gather together all examples annotated with a “Lunch” label, while on the other, we gather all the remaining examples together as the same kind of data. Once the training of each classifier is complete, classifying a new appointment is a two-fold process: (i) classifying the appointment according to each separately-trained binary SVM and (ii) inferring the final class of this appointment based on the result returned by each classifier (e.g. using a voting method).
The evolution of Machine Learning and NLP has led to the emergence of ‘intelligent’ algorithms and gave birth to Julie. Thanks to these advances, Julie is now here to answer your requests and organize your appointments. But, this is just the beginning; deep learning is currently shaking up the field of AI, delivering excellent results using methods based on artificial neural networks. Julie could yet have more surprises in store for you…
For more information or comments, feel free to visit our FAQ page or contact our team.