
Dans le cadre de la sortie du livre « L’Intelligence Artificielle par la pratique », rédigé par Boi Faltings et Michael Schumacher, les Presses Polytechniques Universitaires Romandes, partage avec nous un article qui reprend les bases de l’IA. Et oui, l’IA on en parle beaucoup mais savez-vous exactement ce que c’est ? Cet article est pour nos lecteurs un peu geeks qui veulent comprendre ce qui se cache derrière notre chère Julie 🙂

L’intelligence artificielle constitue l’un des fondements de l’informatique contemporaine et joue un rôle fondamental dans de très nombreuses applications. Dès le début de l’informatique, les chercheurs se sont tout particulièrement intéressés à la reproduction de l’intelligence humaine sur ordinateur. C’était la motivation principale pour aller au delà de la simple machine à calculer vers des automates capables de traiter l’information en général de façon intelligente.
La première utilisation du terme « Intelligence artificielle »
 Le but des premiers ordinateurs était de réaliser de grands calculs, en particulier de trajectoires d’obus d’artillerie. Leur première utilisation en dehors des calculs numériques fut de casser des codes cryptographiques dans un projet mené par le mathématicien Alan Turing. Il fut l’un des premiers à développer une vision beaucoup plus large des ordinateurs et à formaliser cette vision dans des modèles théoriques comme la machine de Turing. Il considérait les ordinateurs comme de véritables cerveaux électroniques, capables de beaucoup plus que du simple calcul.
Le but des premiers ordinateurs était de réaliser de grands calculs, en particulier de trajectoires d’obus d’artillerie. Leur première utilisation en dehors des calculs numériques fut de casser des codes cryptographiques dans un projet mené par le mathématicien Alan Turing. Il fut l’un des premiers à développer une vision beaucoup plus large des ordinateurs et à formaliser cette vision dans des modèles théoriques comme la machine de Turing. Il considérait les ordinateurs comme de véritables cerveaux électroniques, capables de beaucoup plus que du simple calcul.
Pendant l’été 1956, un groupe de chercheurs s’est réunit au collège de Dartmouth (New Hampshire, USA) pour une conférence d’un mois. Il y avait là des chercheurs qui allaient devenir très influents, tels que l’organisateur John McCarthy et Herbert Simon, qui allait recevoir plus tard le prix Nobel. A cette époque, la puissance des ordinateurs progressait rapidement, et il paraissait évident qu’ils allaient égaler ou dépasser l’intelligence humaine au bout de peu de temps. La conférence a donc inventé le terme « Intelligence Artificielle ».
L’IA, simulation de pensée et intelligence humaine
Avec l’arrivée d’internet dans la vie de tous les jours, l’Intelligence Artificielle a quitté le monde des laboratoires et de l’industrie spécialisée pour s’intégrer dans les applications que nous utilisons quotidiennement ou encore au service de multinationales. L’Intelligence Artificielle s’est développée de manière fulgurante et les techniques qui furent développées sont à la base de l’informatique telle que nous la connaissons aujourd’hui : la programmation orientée objet et la programmation fonctionnelle en sont issues, de même que les techniques d’analyse de données et d’apprentissage automatiques, qui sont largement répandues.
Les progrès de l’IA se sont signalés par des succès comme le système WATSON qui a battu en 2011 les meilleurs joueurs humains dans le jeu télévisé Jeopardy, ou encore l’assistant personnel SIRI disponible sur certains téléphones mobiles ou les voitures autonomes (sans parler de Julie Desk :).
Avant toute discussion sur les techniques de l’IA, il est nécessaire de prendre connaissance de ses principaux objectifs et raisons d’être. Une définition intuitive est facile à donner : il s’agit de l’étude des programmes informatiques qui simulent la pensée ou l’intelligence humaine. Mais comment définir exactement en quoi cela consiste ?
Les différentes utilisations de l’IA
Les techniques qui sont centrales à l’IA d’aujourd’hui, et qui font son succès dans les applications, sont basées sur l’inférence logique, les algorithmes de recherche et d’optimisation, et diverses techniques statistiques utiles pour l’apprentissage automatique. Elles sont essentielles pour résoudre des problèmes tels que :
- le traitement d’informations non structurées, comme par exemple des textes ou le contenu de pages Web ;
- l’opérationnalisation de données, par exemple la génération de règles qui peuvent être appliquées automatiquement pour implémenter une certaine stratégie ;
- le calcul abductif, par exemple pour planifier ou ordonnancer des opérations afin d’atteindre certains buts ;
- le calcul inductif, par exemple l’apprentissage des préférences d’un utilisateur, la prévision des mouvements de la bourse, ou la détection d’anomalies dans une grande base de données.
L’IA et l’apprentissage
Un aspect important de l’intelligence est la capacité d’apprendre de nouvelles connaissances sur la base d’exemples issus de l’observation du monde. Parmi les trois modes d’inférence, l’apprentissage correspond à l’induction, c’est-à-dire à des raisonnement qui tirent des conclusions universelles à partir de prémisses particulières. On peut distinguer deux types d’apprentissage :
- L’apprentissage supervisé : on fournit au système des exemples avec la bonne classification ou la bonne prédiction ; le système doit alors reproduire cette classification ou prédiction aussi bien que possible. L’apprentissage supervisé s’applique par exemple à l’apprentissage de règles pour reconnaître les mauvais payeurs ou les conditions de dysfonctionnement d’un appareil.
- L’apprentissage non supervisé : le système doit lui-même proposer une classification raisonnable, par exemple pour optimiser ses propres critères de performance du système. L’apprentissage non-supervisé peut ainsi servir à grouper les clients d’un site web en classes typiques pour optimiser leur structure d’accès ou à classifier des segments de génome pour distinguer les portions importantes de celles qui ne le sont pas.
L’apprentissage supervisé vise à obtenir un modèle capable de prédire une variable « cible » pour de nouveaux exemples, en utilisant un ensemble d’exemples pour lesquels la valeur de cette variable est déjà connue. On distingue entre la classification, dans laquelle la variable-cible est catégorique, et la régression, dans laquelle la variable-cible prend des valeurs numériques.
L’apprentissage non-supervisé ne s’appuie pas sur des variables-cibles préalablement données, mais vise à obtenir un modèle qui regroupe des exemples similaires. Il est particulièrement utile quand on dispose d’une grande quantité de données non-interprétées. Le but de l’apprentissage est alors de découvrir la structure inhérente à ces données, en général sous la forme d’un regroupement en classes similaires (des clusters).
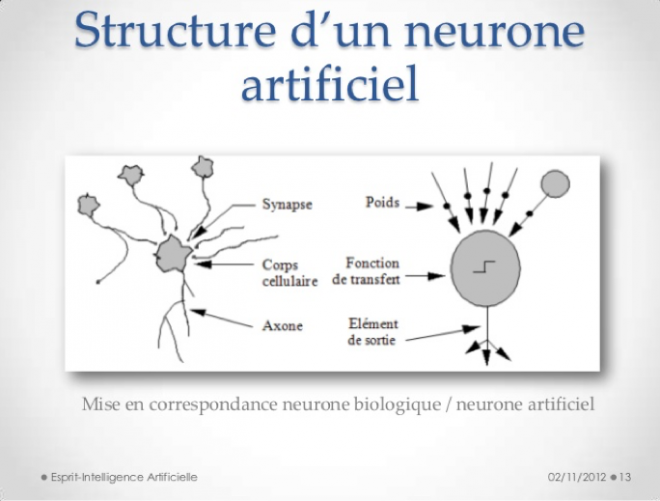
Comme l’apprentissage s’observe avant tout chez les êtres vivants, plusieurs techniques s’inspirent de la biologie. Nous considérons ainsi notamment les réseaux de neurones artificiels, qui imitent la structure du cerveau sous une forme idéalise, et les algorithmes génétiques. Tous les deux permettent un apprentissage supervisé.
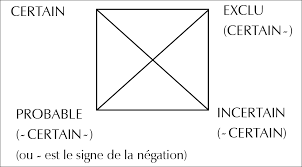
Traitement de l’information certaine et incertaine
Les raisonnements logiques s’appuient sur une distinction nette entre des propositions vraies et des propositions fausses. Dans la réalité cependant, nous sommes souvent confrontés à des situations d’incertitude, dans lesquelles il est difficile d’affirmer que telle ou telle proposition est absolument vraie ou absolument fausse. Ceci arrive pour diverses raisons :
- manque de précision dans les données de départ,
- utilisation d’un raisonnement abductif, dont la conclusion est ambigüe,
- présence de facteurs non-observables qui ont une influence sur la validité du raisonnement.
En principe, chaque proposition qui figure dans un raisonnement peut faire l’objet d’une incertitude. On associe donc à chaque proposition une mesure numérique de vraisemblance, laquelle indique le degré auquel cette proposition peut s’appliquer.
La plupart des systèmes experts modélisent l’incertitude en attachant un certain degré de confiance aux conclusions obtenues. Dans MYCIN, un programme d’intelligence artificielle par exemple, on tient compte de facteurs de certitude (CF) représentés par des nombres réels compris entre −1.0 et 1.0. Un facteur de certitude de 1.0 signifie qu’un fait est absolument certain, une valeur de 0.5 signifie que le fait est vraisemblable, une valeur de 0.0 implique que l’on ignore totalement s’il est vrai ou faux et enfin un facteur de certitude de −1.0 indique que le fait est faux avec une certitude absolue.
Les facteurs de certitude sont attachés aussi bien aux faits qu’aux règles. Lorsqu’une règle donnée est appliquée pour déduire un nouveau fait, le facteur de certitude de ce fait est calculé par combinaison des facteurs de certitude des antécédents de la règle et de celui de la règle elle-même. Ce calcul s’effectue selon la formule suivante :
Traitement de l’information incertaine 115 CF(résultat) = max(min(CF(conditions)),0)•CF(règle)
Un exemple d’application : Le routage de véhicules autonomes
Pour transporter des pièces et des matériaux entre les machines qui les traitent, les usines modernes utilisent souvent des véhicules autonomes. Ceux-ci sont habituellement programmés par des règles de comportement qui définissent une façon de traiter les tâches sans collisions. Les règles doivent être développées pour les situations spécifiques par des experts hautement qualifiés. De plus, il est difficile de concevoir des règles qui fonctionnent même en présence d’imprévus comme des pannes de véhicules.
L’entreprise Lookahead Decisions a remplacé un système à règles par une méthode qui cherche les meilleures combinaisons de chemins par recherche heuristique (A*). Par rapport aux comportements fixes, cette méthode a amélioré le débit de 83%, le temps moyen pour réaliser des tâches de 25% et aussi le nombre d’arrêts de véhicules (une mesure de leur usure) de 48%. En plus, le nouveau système résiste mieux aux changements et ne demande pas d’expert pour la mise à jour des règles de comportement.
Source : Lookahead Decisions Case Study : Real-time routing of automated guided vehicles, www.lookaheaddecisions.com, 2003
L’intelligence artificielle par la pratique
 Cet ouvrage présente l’ensemble des bases du domaine, comme la représentation de connaissances et l’inférence logique déductive, le traitement d’informations incertaines, les méthodes de recherche et de résolution de problèmes par abduction, ainsi que les techniques d’apprentissage automatique supervisées, non supervisées et bio-inspirées. La deuxième édition est complétée par les techniques d’inférence probabilistes et d’apprentissage qui se sont développées récemment. A la différence d’autres ouvrages plus théoriques, ce manuel se veut délibérément pratique et présente l’intelligence artificielle dans le cadre de son application à la résolution de problèmes réels. Afin d’offrir une compréhension optimale de la matière, des applications et de nombreux exercices de programmation résolus sont présentés dans leur intégralité. Ceux-ci permettent au lecteur d’appréhender les mécanismes principaux de la discipline afin qu’il puisse les adapter à ses propres besoins. L’ouvrage est ainsi particulièrement indiqué aux étudiants de dernière année de Bachelor et ceux de Master, ainsi qu’à toutes les personnes qui souhaitent s’initier à l’intelligence artificielle.
Cet ouvrage présente l’ensemble des bases du domaine, comme la représentation de connaissances et l’inférence logique déductive, le traitement d’informations incertaines, les méthodes de recherche et de résolution de problèmes par abduction, ainsi que les techniques d’apprentissage automatique supervisées, non supervisées et bio-inspirées. La deuxième édition est complétée par les techniques d’inférence probabilistes et d’apprentissage qui se sont développées récemment. A la différence d’autres ouvrages plus théoriques, ce manuel se veut délibérément pratique et présente l’intelligence artificielle dans le cadre de son application à la résolution de problèmes réels. Afin d’offrir une compréhension optimale de la matière, des applications et de nombreux exercices de programmation résolus sont présentés dans leur intégralité. Ceux-ci permettent au lecteur d’appréhender les mécanismes principaux de la discipline afin qu’il puisse les adapter à ses propres besoins. L’ouvrage est ainsi particulièrement indiqué aux étudiants de dernière année de Bachelor et ceux de Master, ainsi qu’à toutes les personnes qui souhaitent s’initier à l’intelligence artificielle.
Envie d’un peu de lecture cet été ? Commandez l’ouvrage dès à présent 🙂
Cet article a été rédigé par Presses Polytechniques Universitaires Romandes.